مسیر یادگیری
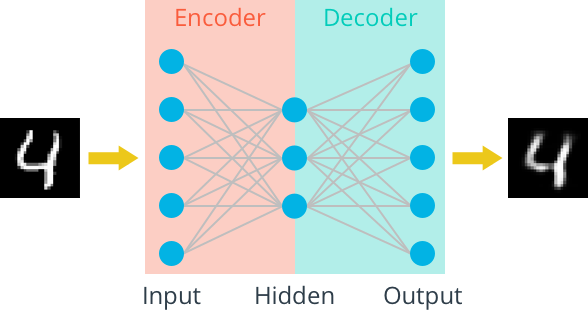
فرض کنید یه تصویر از یه عدد یا یه چهره داریم
Autoencoder این تصویر رو مرحله به مرحله کوچیکتر میکنه تا به یه کد مخفی یا همون latent code برسه — این بخش در واقع مغز شبکهست
بعد Decoder تلاش میکنه از اون کد، تصویر رو دوباره بازسازی کنه.
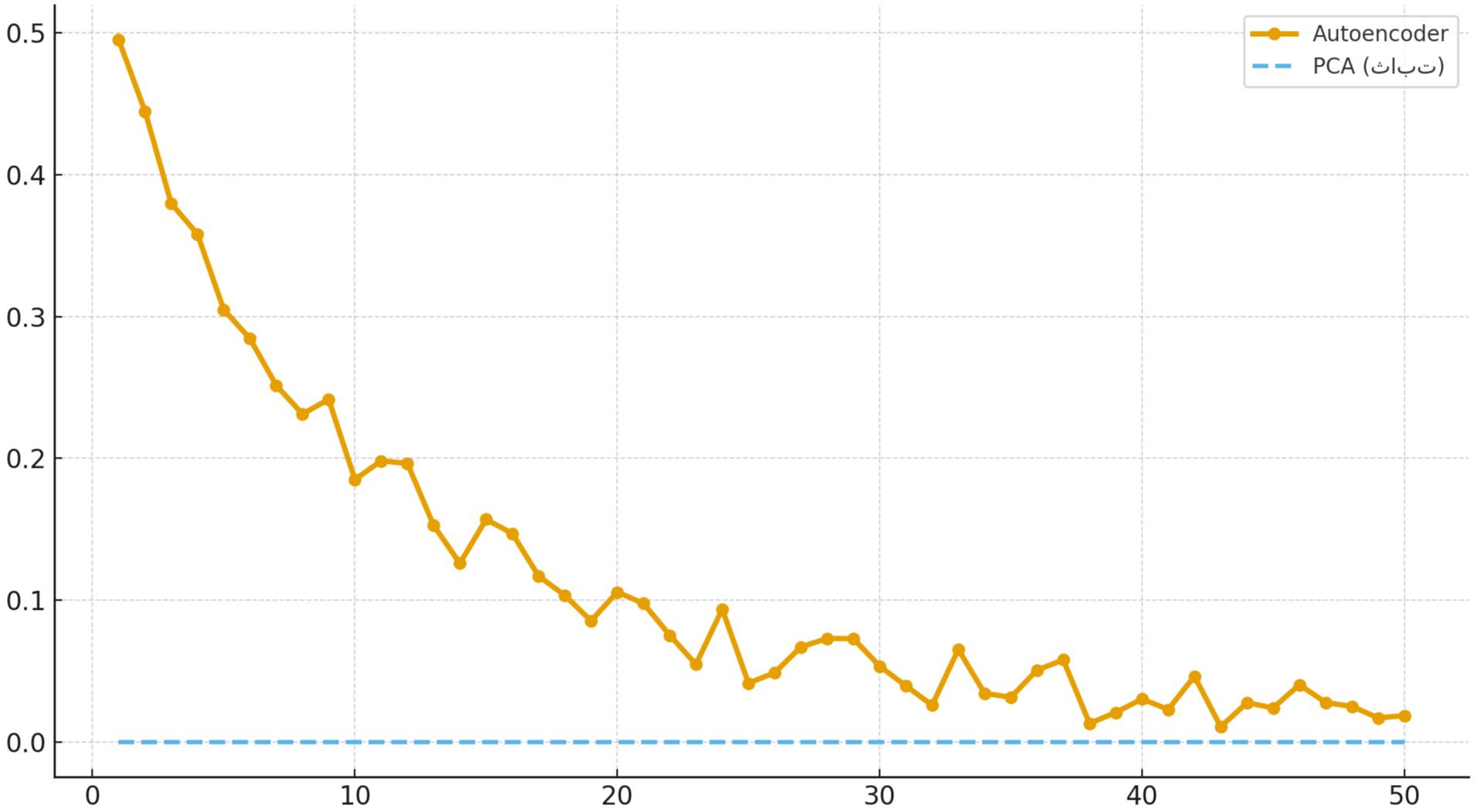
تفاوت بین تصویر اصلی و بازسازیشده به عنوان خطا اندازهگیری میشه،
و شبکه به مرور زمان یاد میگیره این خطا رو کمتر کنه تا بازسازی دقیقتری انجام بده.